Meta 新百萬位元組系統解決 GPT 最大障礙之一
Meta AI 的研究人員可能已經開發出一種方法來解決 GPT 模型的“標記化”問題
Meta AI 最近發布預印本研究,展示一種用於建構生成式預訓練轉換器 (GPT) 系統的全新“百萬位元組(Megabyte)”框架。
OpenAI 的前特斯拉人工智慧總監 Andrej Karpathy 稱其為“有前途的”,新架構旨在處理大量數據,例如圖像、小說和影片文件,而無需使用稱為標記化(tokenization)的過程。
標記化是一個有損過程,可與文件壓縮相媲美,為了處理大量數據,GPT 模型將位元轉換為標記,然後,令牌由轉換器處理並用於生成輸出記號,然後對其進行解碼。
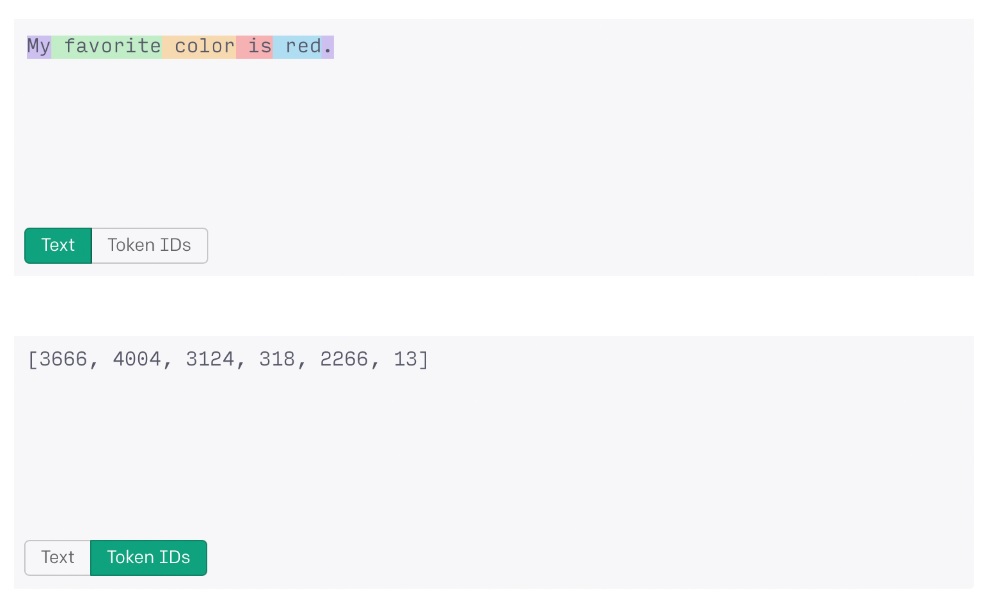
標記化過程允許 AI 系統將更大的數據字符串處理為數字。例如,“我最喜歡的顏色是紅色”這句話如果被 OpenAI 的 ChatGPT 處理,將被轉換為記號字符串“3666、4004、3124、318、2266、13”進行處理。
不幸的是,即使透過標記化,當前最先進的系統可以處理的數據量仍然有硬性限制,對於 GPT-3.5,限制略高於 4,000 個標記或約 3,000 個單詞,而 GPT-4 的最大值約為 32,000 個標記或約 24,000 個單詞。
Meta 的新百萬位元組系統放棄標記化,轉而支持一種新穎的多層預測架構,該架構能夠對超過一百萬字節的數據進行端到端建模。
大多數標準的英語語言編碼系統使用標準的 8 位編碼,在此範例中,每個字符佔用一個字節的數據,因此,無需標記化即可處理一百萬字節數據的 AI 系統可以處理包含七百五十萬個單詞的文本文檔,比 GPT-4 增加 3,025%。
相比之下,GPT-4 目前可以在單個提示中處理大約 10 篇長篇新聞文章,而百萬位元組將能夠解析整個 Leo Tolstoy 的《戰爭與和平》以及另外兩部中等長度的小說。
Meta 的百萬位元組模型在與處理音頻文件相關的 ImageNet 測試和基準測試中也表現出色,在以下兩個方面均等同於或超過現有的以字節為基礎轉換器模型,例如 DeepMind 的 Perciever AR:
“百萬位元組與 PerceiverAR 的最先進性能相媲美,同時只使用一半的計算。”
這項研究的影響可能是深遠的,由於其硬數據限制以及訓練系統所需的能量和時間,標記化被認為是該領域的障礙。
如果沒有標記化,應該可以訓練出對非英語語言有更強基礎支持的 AI 模型,尤其是那些不能輕易用標準 8 位字符編碼的語言。
這可能會導致這些技術的進一步民主化,並使從加密貨幣交易機器人到去中心化自治組織技術的一切都能夠以世界各地的本地語言代碼構建。
它還可以透過使用與文本大致相同的時間和能源消耗來生成多媒體剪輯,從而提高 ChatGPT 等模型處理圖像、影片和聲音文件的能力。
標記化過程的 OpenAI 演示。From OpenAI
※版權所有,歡迎媒體聯絡我們轉載;登錄本網按讚、留言、分享,皆可獲得 OCTOVERSE 點數(8-Coin),累積後可兌換獎品,相關辦法以官網公布為準※