Google AI 研究人員推出 DiarizationLM:機器多語音識別學習框架,利用大型語言模型 (LLM) 對語音分類輸出進行後處理
在音訊處理中,語音分類是一項關鍵但具有挑戰性的任務。
多語音識別分類技術對於在多人說話者環境中辨別個人聲音至關重要,在各種應用中具有巨大的價值。從提高電話會議的清晰度到幫助轉錄法律程式,其效用是深遠的。儘管這項任務很重要,但卻相當複雜。傳統的日記化方法雖然先進,但經常會遇到語音重疊和語音調製變化等問題,導致在識別“誰在什麼時候說話”方面不準確。
為了應對這些挑戰,研究界採用了一系列方法。大多數分類系統的骨幹是語音活動檢測、說話人輪流檢測和聚類演演算法的組合。這些系統通常分為兩類:模組化和點對點系統。模組化系統由單獨訓練的元件組成,每個元件處理分類的特定方面。相反,點對點系統旨在使用複雜的損失函數來優化整個分類過程。然而,這兩種方法都有局限性,特別是在涉及重疊語音或不同說話風格的場景中。
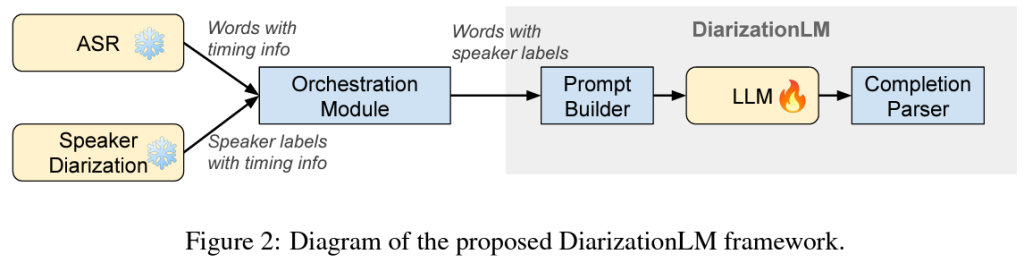
進入“DiarizationLM”,這是一個由Google研究人員開發的突破性框架,有望通過利用大型語言模型 (LLM) 的強大功能來徹底改變說話人的日記化。這種創新方法從自動語音辨識 (ASR) 和說話人分類系統中獲取輸出,並使用 LLM 對其進行優化。它涉及一個後處理步驟,通過解釋語音的語義和上下文細微差別來提高說話人歸因的準確性。該框架代表了從單純依賴聲學信號到整合語音內容中嵌入的豐富信息的轉變。
DiarizationLM 的內部工作原理與其前提一樣引人入勝。它首先將 ASR 和說話人分類系統的輸出轉換為緊湊的文字格式。此格式可作為 LLM 優化分類結果的提示。通過分析文本內容,LLM 可以更準確地將語音片段歸因於正確的說話者,從而減少分類錯誤。該框架採用微調模型(如PaLM 2-S)來針對和糾正這些診斷不準確之處。
DiarizationLM的性能令人印象深刻。其功效通過顯著降低單詞日記錯誤率來證明。在 Fisher 和 Callhome 數據集上進行測試時,該框架的單詞日記化錯誤率分別相對降低了 25.9% 和 31%。這些數字證明瞭該框架能夠提高說話人分類系統的精度。更重要的是,這些改進是在不同的語音領域觀察到的,展示了DiarizationLM的多功能性。
DiarizationLM 證明了說話人日記化的發展格局。它通過將大型語言模型的分析能力集成到日記化輸出的後處理中,解決了準確說話人歸因的長期挑戰。這一進步標誌著語音處理系統技術能力的重大飛躍,併為對多說話者音訊進行更細緻和準確的解釋鋪平了道路。DiarizationLM 具有顯著減少語音化錯誤的能力,有望重新定義說話人語音化標準,使其成為任何以破譯單個語音為關鍵的場景中的寶貴工具。
※版權所有,歡迎媒體聯絡我們轉載;登錄本網按讚、留言、分享,皆可獲得 OCTOVERSE 點數(8-Coin),累積後可兌換獎品,相關辦法以官網公布為準※