
谷歌詳細介紹 TPUv4 及其瘋狂的光網可重構 AI 網路
在 2023 熱門晶片的網路論壇上(HOT CHIP 2023),谷歌展示了其瘋狂的光學可重構 AI 網路。該公司正在進行光電路切換,以實現其AI訓練叢集的更好性能,更低功耗和更大的靈活性。更令人驚訝的是,他們已經實際運作了多年。
來源: SERVERTHEHOME
這樣做的最大目標是將Google TPU晶片捆綁在一起。
第四代突破性性創新系統特點
1. 光網交換器 OCS
2.第三代內崁是輔助處理器 Sparecore
3. 領先業界的電腦功耗
4. 4096個晶片共享256 TiB 的HBM 記憶體
5. 從2020 起開始實際運作的 hyperscale 架構
這是7nm Google TPUv4。我們預計本周我們將開始聽到更多關於TPUv5的資訊。谷歌通常可以做關於一代舊硬體的論文和演示。TPU v4i 是推理版本,但這更像是 TPUv4 的重點談話。

谷歌表示,與典型功率相比,配置了超額的計算能力,因此它可以滿足5ms的時效服務保證服務SLA。因此,晶片上的TDP要高得多,但這是為了因應突發峰值運算以達到SLA的要求。
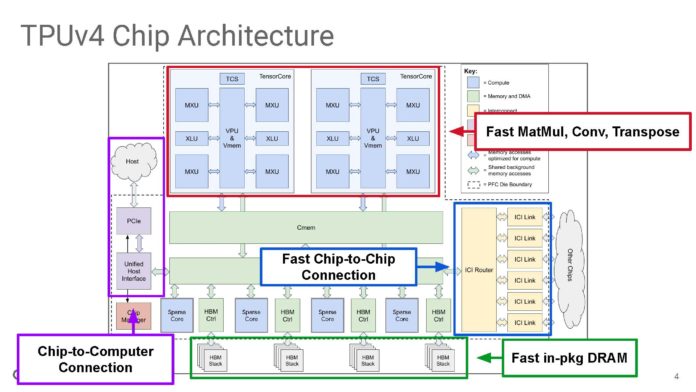
下面是 TPUv4 系統結構圖。谷歌製造這些TPU晶片不僅僅是一個加速器,而是作為大規模基礎設施的一部分進行擴充和營運。
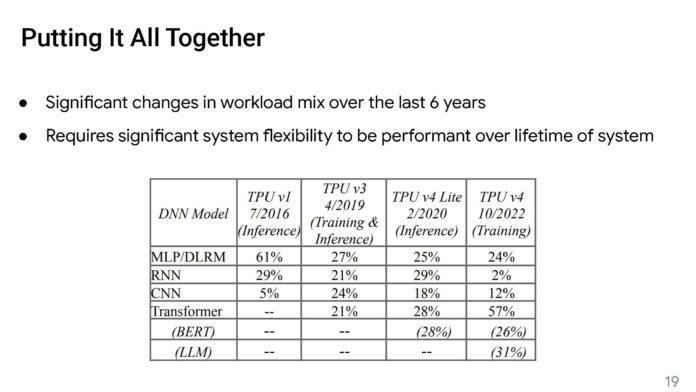
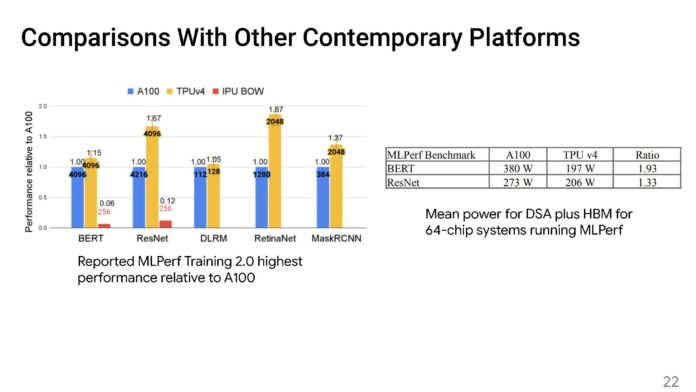
以下是Google TPUv4與TPUv3的統計數據,這是我們見過的最清晰的表格之一。
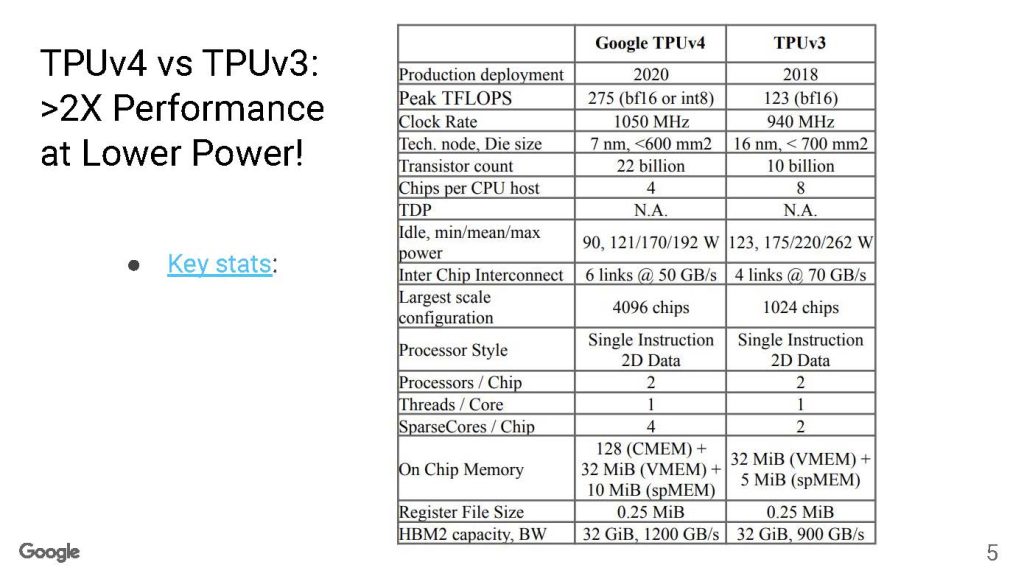
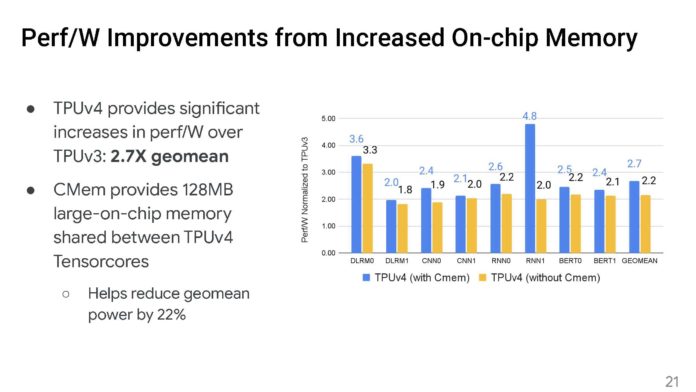
谷歌的峰值FLOPS增加了一倍多,但降低了TPUv3和TPUv4之間的功率。
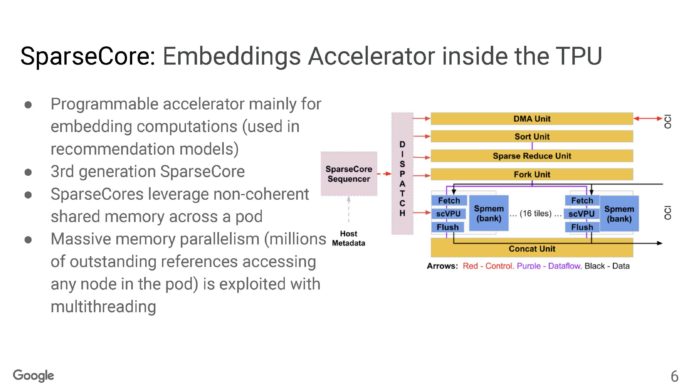
Google在TPUv4中內置了一個SparseCore加速器。
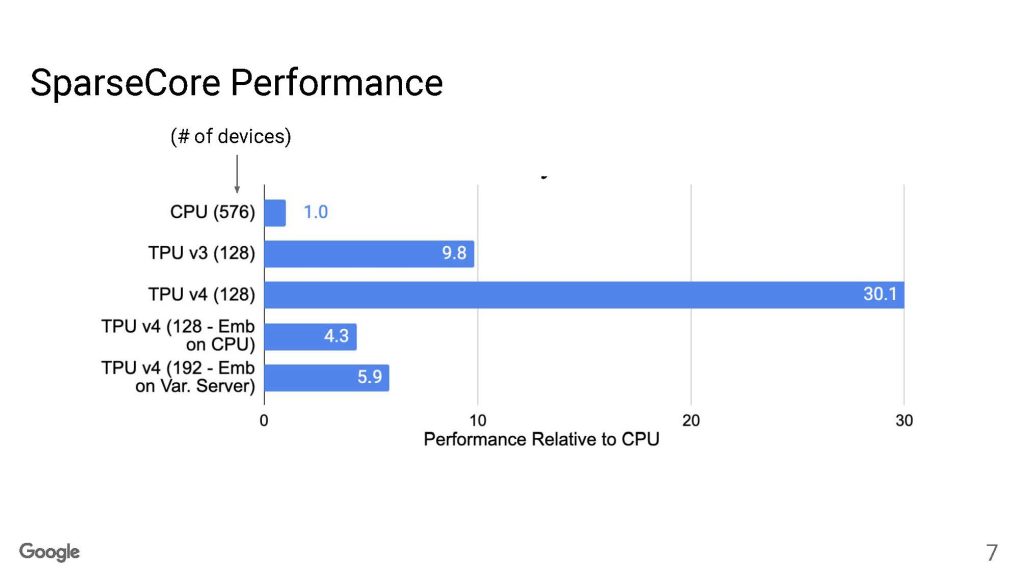
這是谷歌的TPUv4 SparseCore 性能。
該板本身有四個 TPUv4 晶片,並且是液冷的。谷歌表示,他們不得不重新設計數據中心和運營以改用液體冷卻,為了節省電力是值得投資的。右側的閥門控制流經液體冷卻管的流量。谷歌表示,它就像一個風扇速度控制器,但用在液體上。

谷歌還表示,由於這是 2020 年的設計,所以還是使用 PCIe Gen3 x16 。
像許多數據中心一樣,谷歌有能力從機架頂部進入,但它有許多互連。在機架內,谷歌可以使用電動DAC,但在機架外,谷歌需要使用光纜。
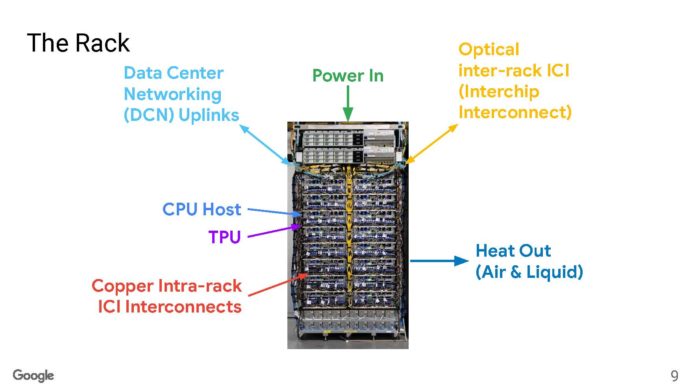
每個系統有64個機架,帶有4096個互連晶片。從某種意義上說,NVIDIA 在 256 個節點上的 AI 叢集擁有一半的 GPU。

同樣在機架的末端,我們看到一個CDU機架。谷歌表示,液體的流速高於鉤子和梯子消防車軟管中的水。
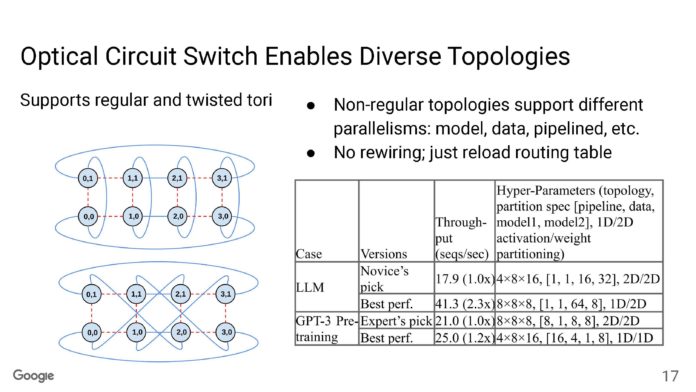
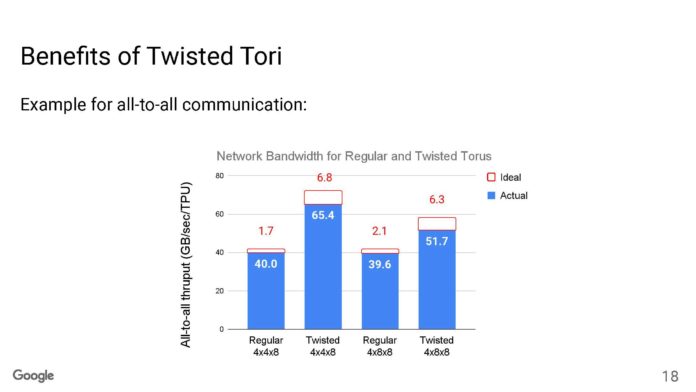
每個機架都是一個 4x4x4 立方體(64 個節點),TPU 之間具有光網路切換 (OCS)。在機架內,連接是DAC。立方體的面都是光學的。
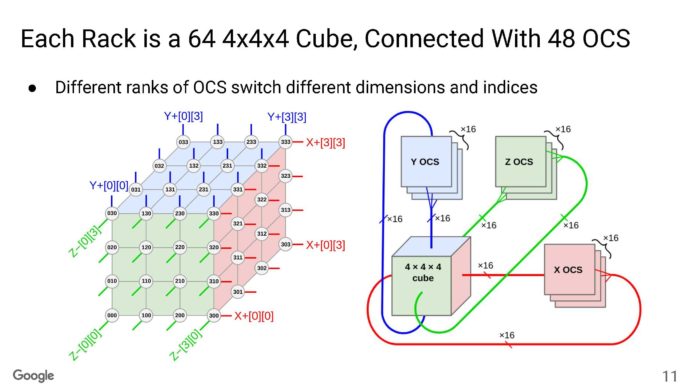
以下是OCS的介紹。使用OCS不是使用電子網路交會氣,而是在晶片之間提供直接連接。谷歌擁有內部2D MEMS陣列,鏡頭,相機等。避免所有網路延遲可以更有效地共享數據。順便說一句,這在某些方面感覺類似於 DLP 電視。

谷歌表示,它在超級機貴組中擁有超過16000個接點和足夠的光纖距離,可以環繞羅德島。

因為有這麼多的點對點通信,所以需要大量的光纖束。
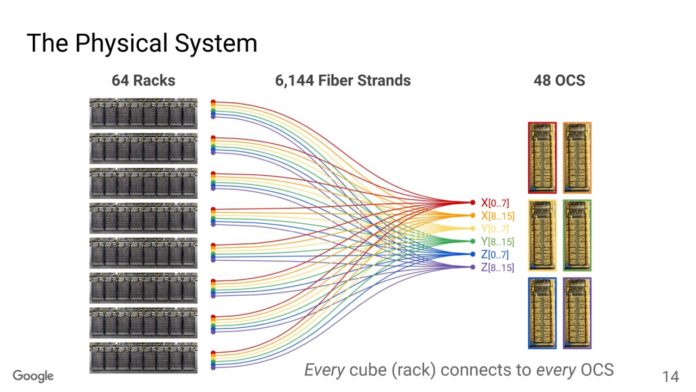
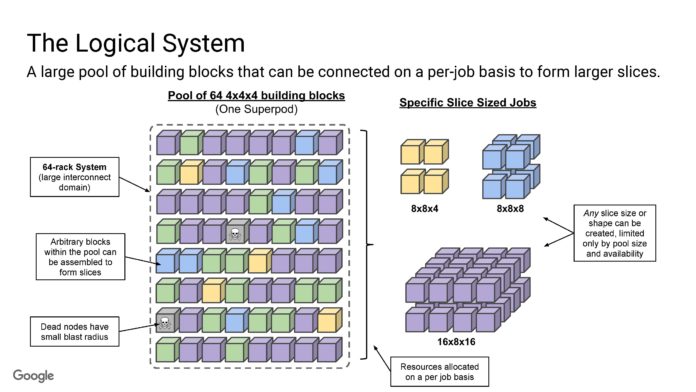
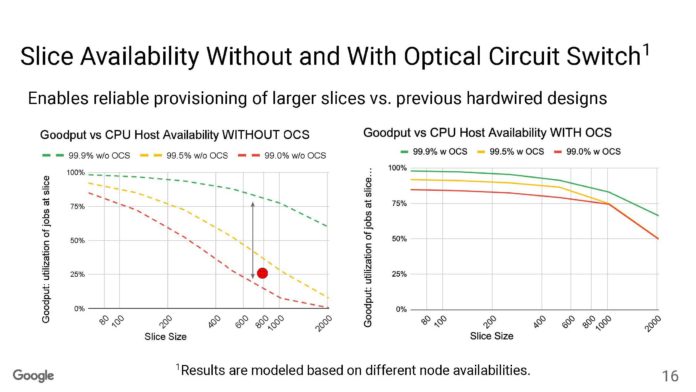
OCS 由於是可重新配置的,因此可以提高節點利用率。
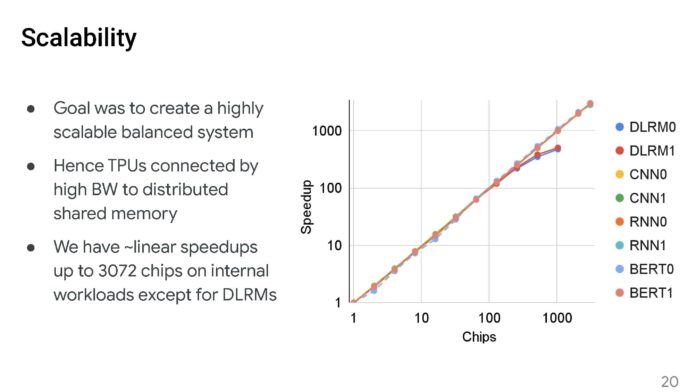
這是谷歌在對數尺度上的擴充,在多達 3072 個晶片上線性加速。
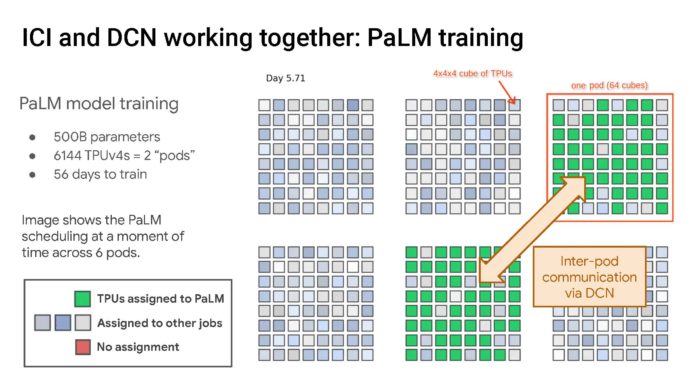
這是在兩個機櫃組中訓練 6144 個 TPU 的 PaLM 模型。
這是一個巨大的數位架構!
結語
現在是谷歌開始談論TPUv5的時候了,碰巧谷歌的下一個是本周。儘管如此,這種光互連仍然是一項真正的創新技術。
現在很明顯的是,谷歌在用龐大的基礎設施解決巨大的問題。它更有機會進入人工智慧領域。這裡有一個問題,谷歌會以多快的速度將其人工智慧硬體和雲服務與nvidia 競爭,同時還需要為其客戶購買NVIDIA GPU 提供服務,而不是使用自己的TPU。
※版權所有,歡迎媒體聯絡我們轉載;登錄本網按讚、留言、分享,皆可獲得 OCTOVERSE 點數(8-Coin),累積後可兌換獎品,相關辦法以官網公布為準※
















